ControlNet – Это расширение для нейросети Stable Diffusion, которое позволяет копировать вам композицию изображения и позу человека. Кто уже попробовал генерировать картинки – наверняка знают, как сложно заставить принять человека на иллюстрации именно ту позу, которая сейчас необходима. Довольно часто получается дикий рандом и бесконечная генерация до момента, пока подвернется что-то действительно ожидаемое. ControlNet решает эту задачу и полностью меняет представление о возможностях нейросети.

В этой заметке вы узнаете все что нужно для работы с ControlNET. Как установить и применить в интерфейсе от Automatic1111, расскажу о настройках и возможностях… конечно же рассмотрим реальные примеры и варианты где это можно использовать.
- Что такое ControlNET?
- Canny – отрисовка краев
- Человеческие позы
- Что умеет ControlNET
- OpenPose – Определение позы
- Canny – рисуем границы
- Lineart – детектор прямых линий
- Scribble
- Soft Edge или HED
- Segmentation
- Depth
- Установка расширения в StableDiffsuion от Automatic1111
- Использование ControlNET
- Настройка Промта или текста в картинку
- Параметры ControlNET
- Описание основных настроек ControlNET
- Основные элементы расширения
- Препроцессор и модель
- Control Weight и что-то со Step
- Обращение к читателям
Что такое ControlNET?
ControlNET – это специальное расширение для Stable Diffusion. Мы уже понимаем, что базовая нейросеть умеет преобразовывать текстовые подсказки (PROMPT) в готовое изображение. Простыми словами – из текста получаем картинку. ControlNET позволяет нам использовать еще несколько возможностей указать – чего нам вообще надо! Позвольте мне показать вам некоторые примеры, которыми вы обязательно захотите воспользоваться
Canny – отрисовка краев
На картинке ниже ControlNET извлекает из входной картинки контуры используя препроцессор Canny. Данное изображение сохраняется и используется при генерации изображения в дополнении к вашему текстовому запросу.
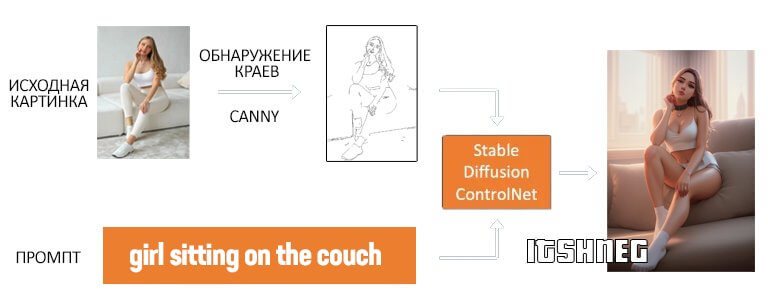
Запомним сразу! Препроцессор – считывает информацию из вашего изображения. Модель – использует извлеченную информация для генерации картинки. Это очень важно не забывать, по моему опыту – тут обычно больше всего вопросов.
Человеческие позы
Теперь самое интересное! Сколько времени и нервов было потрачено на понятное описание человеческой позы? – Есть простое и элегантное решение. Openpose – это модель определения ключевых точек, которая позволяет подсказать нейросети где у нас голова, ноги и руки!


В чем разница между Canny и OpenPose? Canny работает со всем изображением, не только с объектом. Таким образом сцена передается более точно. На примере работы вы можете увидеть что частично сохранилась даже одежда!
OpenPose определяет только позиции ключевых точек в кадре (уши, нос, коленки и прочие…) и служит для вычленения позы человека, в этом случае абсолютно неважно, что происходит вокруг и во что одет персонаж – берется только поза.
Что умеет ControlNET
Пришло время познакомиться со всеми возможностями этого расширения. Я на примере покажу работу каждой модели.
OpenPose – Определение позы
Копирование позы на основе ключевых анатомических точек. Копируется только поза без деталей вроде пола, прически, фонового изображения…



Canny – рисуем границы
Наверное самый понятный препроцессор и модель. Берем контуры изображения и используя их пытаемся нарисовать новую картинку по вашему запросу.



Lineart – детектор прямых линий
ControlNET может стараться выбирать на изображении прямые линии. Это полезно для дизайна интерьера, зданий и еще много где. Мне нравится даже больше чем CANNY.



Остальные модели достаточно сложно поддаются описанию, поэтому приложу наглядный пример работы из описания с официального сайта.
Scribble
Чем то напоминает inpaint Sketch в виде наброска для будущей иллюстрации. Препроцессор тут не имеет смысла использовать – данные мы извлекаем из своей головы.

Soft Edge или HED
Выводит вокруг объекта плавные и мягкие контуры. В большинстве случаев имеет использовать именно этот вариант – так сказать Canny на максималках.

Segmentation
Разделяет изображение на несколько участков. Тут действительно проще один раз увидеть…

Depth
Генерируется карта глубины изображения. Очень часто используется для выделения объектов или персонажей и абсолютно не подходит для пейзажей и прочих подобных изображений.

Установка расширения в StableDiffsuion от Automatic1111
Предлагаю перейти к установке ControlNet в веб интерфейсе от Automatic.
Для загрузки расширения перейдите на вкладку Extensions > Install From URL, введите адрес ниже в окно “URL for extensions git repository” и нажмите Install. В какой-то момент вам может показаться что ничего не происходит – просто дождитесь!
https://github.com/Mikubill/sd-webui-controlnet
Перезагрузите StableDiffusion и перейдите на вкладку txt2img и переместитесь вниз. Если у вас присутствует пункт “ControlNet vXXX”, то вы успешно установили расширение.

Для работы с КонтролНЕТ необходимо предварительно загрузить модели, которые будут встраиваться в формирование изображения. Ранее они весили очень много, но с обновлением стало несколько полегче. Нас интересуют файлы с расширением *.pth (это самые большие) – они всегда доступны на странице:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
После загрузки их необходимо разместить в папке StableDiffusion
stable-diffusion-webui/extensions/sd-webui-controlnet/models
Вам вовсе необязательно загружать все модели. Если вы впервые используете ControlNet – вы наверняка хотите разобраться с позами для размещения персонажа – за это отвечает модель control_v11p_sd15_openpose.pth.
Использование ControlNET
Вы добрались до раздела с описанием процесса работы с расширением (наконец-то)… чуть ниже я расскажу о каждом пункте настроек.
Итак – у нас установлено расширение. Разворачиваем кликнув по названию и видим различные параметры с полем для изображения.

Я не стал брать для примера изображение из интернета, а быстренько сгенерировал свое. Ее мы возьмем в дальнейшую работу – проведем все эксперименты 🙂

Настройка Промта или текста в картинку
Тут все как обычно: на вкладке txt2img напишите требуемый промт и по желанию negative (подробнее в статье о правильном написании PROMPT). Я хочу чтобы девушка стояла на фоне ночного города в стиле киберпанка. В итоге наш Промт выглядит так:
posing slavic woman 30 yo, neon green hair, little ponytail (figurativism:0.8), (night cyberpunk city:1.3), jeans short
Установите разрешение будущей картинки (в идеале оно должно совпадать с изображением, которое вы используете в ControlNet – обычно я заранее их подготавливают в Photoshop или аналогах). Хочу обратить внимание – размеры иллюстрации задаются именно здесь, на вкладке txt2img, а не под спойлером в ControlNet.
В моем случае размеры 512*768 пикселей – идеально для вертикальных изображений.

На картинке выше указаны мои параметры для генерации. Добавлю, что я использую свою любимую модель RevAnimated, она просто идеально подходит под арты, но совершенно не умеет в реалистичность.
Параметры ControlNET
Теперь приступаем к самому интересному, а именно настройкам ControlNet.
Добавьте исходное изображение на холст (можно выбрать в проводнике или же использовать сочетание CTRL + V, если оно у вас скопировано в буфер обмена).
Поставьте галочку Enable (Включить).
Теперь выбираем препроцессор и модель. В нашем случае для работы с позами мы используем препроцессор openpose_full и модель control_v11_sd_openpose. Настройки КонтролНет на моем примере приведены ниже.

На этом все – жмем самую большую кнопку “Generate” чтобы начать процесс извлечения позы и применением ее в новой иллюстрации.
По окончанию процесса вы увидите как минимум 2 картинки. Это ваше итоговое изображение и ключевые точки расположения человека созданные препроцессором openpose для использования в новой генерации.


Вы можете менять абсолютно все, писать полностью непохожий промт и все время будете получать одинаковую позу. Я попросил нейросеть сгенерировать мне по запросу 6 картинок – все они уникальны, но на них всегда одинаковая поза!

Описание основных настроек ControlNET
Множество чекбоксов может несколько напугать – на первый взгляд может показаться что параметров очень много и совершенно непонятно для чего они нужны, давайте попытаемся объяснить их назначение.
Основные элементы расширения

Панель с изображением: Входное изображение, на основе которого происходит генерация размещается именно здесь. Это изображение будет использоваться выбранным вами препроцессором для создания карты будущей иллюстрации.
Значок камеры: Вы можете использовать веб камеру для получения входного изображения. Для работы необходимо предоставить доступ к камере вашему браузеру.
Enable: Включает работу ControlNet.
Low VRAM: Необходимо использовать, если у вас маленький объем видеопамяти на компьютере (менее 8 гигабайт). Чем выше размер изображения, тем больше потребуется памяти. ControlNet требует большое количество вычислительной мощности и сильно снижает производительность увеличивая время генерации.
Препроцессор и модель
Preprocessor: обработка, которая переводит входное изображение в формат, который понимает модель ControlNet для использования в генерации.
Если у вас имеется заготовка для генерации (например уже скачали коллекцию поз из интернета), то использовать препроцессор не нужно!
Model: Используемая модель ControlNet в StableDiffusion. Обычно соответствует препроцессору. Их достаточно просто сопоставить по совпадению в названии и несколько препроцессоров могут использовать одну модель!
Control Weight и что-то со Step

Weight: значимость ControlNet в процессе генерации изображении относительно вашего промта. Если вы напишите “Стоящая женщина”, а в качестве исходного изображения будете использовать картинку, где она сидит – в итоге вы получите позу соответствующей входному примеру, т.е. человек будет изображен сидящим.
Starting Control Step и Ending Control Steps: Новые параметры КонтролНет, которые появились с обновлением. Раз вы читаете эту заметку, то наверняка уже понимаете принцип работы Stable Diffusion. Вы сами выбираете какое количество шагов будет создаваться иллюстрация и этими параметрами можете указать в какой момент будет использоваться ControlNet, а когда нет. По сути это более гибко настраиваемый параметр Weight – попробуйте поэкспериментировать, достаточно часто это дает более гармоничный результат.
Рассмотрим как работает Weight на примере, возьмем изображение из интернета и используя модель openpose прогоним через ControlNet с разным значением Weight. Ниже исходное изображение и картинка на ее основе со стандартными параметрами.

Теперь будем уменьшать значение ВЕС в ControlNET и отслеживать результаты…



Думаю из примера выше понятно как работает значимость ControlNet для вашего изображения. Это практически невозможно объяснить человечески – лучше прогнать пару генераций и посмотреть самим.
Обращение к читателям
Мы рассмотрели пример работы ControlNet на изображениях с позой человека. Позы в Stable Diffusion – это большая проблема и она полностью решается сегодняшним расширением. Появление ControlNet вывело использование нейросети на качественно новый уровень и описать все возможности в рамках одной заметки просто невозможно. Поэтому, если у вас есть вопросы по какому либо из пунктов – пишите в комментарии, расширим статью по необходимости!





Совершенно непонятно как использовать готовую картинку позы в openpose. Если я просто загружаю только ее, то controlnet не подхватывает. А если нажимаю препроцессор, то он перегенерирует её в черный квадрат. Посоветуйте последовательность действий как правильно работать с готовыми позами?
Если уже есть готовая поза, то необходимо выбрать модель, но убрать препроцессор. Если не получится – заходите к нам в группу в тг, там подскажем